NLP | To begin with…
While experts may debate exactly what makes a human being human, there are a couple of unique traits that everybody agrees upon. One of those traits is Language: the capacity to communicate one’s thoughts, ideas, and feelings to others through a highly complex system of vocal, visual, and orthographic signals. No other species on earth can do that in the same way or with the same level of complexity.
For millennia, people have written down their thoughts, ideas, and feelings and passed those documents to their posterity, thus providing the opportunity for the next generation to read those writings and thereby improve upon the previous generation. That constant improvement has continued such that today technology facilitates rapid communication almost without boundaries or borders.
Since much of the time these communications are recorded (voice messages, blogs, social media, etc.) and since computing power has increased tremendously, for the first time in history we have the singular opportunity to cull that data and analyze it rigorously. A computer, however, is not optimized to understand cues as highly complex as human language. Computers can handle ones and zeros with ease, but language is far more complicated than ones and zeros. Several decades ago, Linguistics Departments and Computer Science Departments at various academic institutions started teaming up to figure out a way to structure language so that a computer could understand it (and even produce it). That’s where natural language processing (NLP) enters the scene.
What is Natural Language Processing?
If I ask this question to five different people, two of them won’t know what it is even though they very likely benefit from it every day and the other three will potentially give quite different responses. To help clarify the situation and to define the possibilities, I prefer to categorize NLP into three high-level categories that are relevant to data science and text analytics:
- Text Processing
- Speech Processing
- Sentiment/Emotion Analysis
The first two equate to the types of data that organizations typically possess while sentiment/emotion analysis is more of a technique that is a subtype of the other two but represents an important enough task to justify its own category.
Text Processing
By far, the vast majority of linguistic data that is available to organizations comes in the form of text. With the advent of texting and social media, the amount of this type of data has skyrocketed to astronomical quantities. The amount of text available only adds to the complexity. A human annotator or analyst could only hope to fumble through less than 1% of all of the data available, leaving the other 99% untapped (a very poor prospect when trying to comprehend entire markets and industries and act on that information). But with the help of a computer that has been programmed to understand human language, that void gets filled by parsing all of the available data and thereby structuring what was previously unstructured. The newly structured text data can then be added to modeling efforts to help during text and predictive analysis. The output of the analysis is action-oriented feedback that leads to optimum solutions to business challenges.
The following example will help illustrate what NLP does to structure text.
In this example, there are key pieces of information (called “entities”), an overall structure (grammar), and semantics (meaning) that undergirds the lexical/grammatical structure. What is called “NLP” actually spans a rather large spectrum from simply identifying just the entities to fully analyzing the syntactic and semantic structures in the sentence. Let’s follow a possible data flow from beginning to end using this example sentence.
- Identify the words:
- Imagine Dragons | is | an | American | rock | band | from | Las Vegas| , | Nevada | .
- Tag each word with a part of speech:
- Noun | Verb | Article | Adjective | Adjective | Noun | Preposition | Noun | Punctuation | Noun
- Identify the named entities (entities that refer to names):
- Imagine Dragons, American, and Las Vegas, Nevada
- Identify larger phrases (called shallow parsing):
- [NP Imagine Dragons] [VP is [NP an American rock band] [PP from [NP Las Vegas, Nevada]]]
- NP = Noun Phrase, VP = Verb Phrase, PP = Prepositional Phrase
- Put those larger phrases together into a full representation of the whole sentence
- [Sentence [NP Imagine Dragons] [VP is [NP an American rock band] [PP from [NP Las Vegas, Nevada]]]]
- Traverse the full parse structure in (5) and derive the semantic relations between the words
- Imagine Dragons – is (Subject)
- is – band (Direct Object)
- Imagine Dragons – band (Copular)
- band – rock (Descriptor)
- band – American (Descriptor)
- band – an (Determiner)
- band – Las Vegas, Nevada (Location)
- Las Vegas, Nevada – from (Prepositional)
The structures in 1, 2, and 3 are relevant to information extraction (pulling out specific pieces of information useful for some analysis task). The structures built in 4, 5, and 6 produce the semantic relationships that exist between the words in the sentence. Each step in the process adds structure and context to the data which can then be used as features for various higher level tasks such as classification and predictive modeling. This process takes unstructured data and structures it with linguistic information, a crucial key in facilitating computational understanding of highly complex linguistic information.
NLP Speech Processing
Before there was writing (text) there was speech. Some of the earliest writings that have been discovered date back roughly 5000 years. But humans have been communicating for a lot longer than that. Today, speech recordings abound, giving organizations an unprecedented amount of speech data to analyze. Using NLP techniques, it is possible to break down speech recordings into words, the units that constitute words, and the meta-information that comes with speech (such as intonation) to better understand what is being said. Further, those speech cues can be gathered and added to predictive models that will aid in understanding what the possible outcomes may be when an organization changes something about their business that affects their clients’ interactions with the organization.
Below is an example of a spectrogram, a tool used to visualize the sound waves of an utterance and the vibrations of the vocal cords during that utterance.
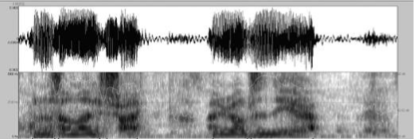
The top portion represents the sound waves after they leave a speaker’s mouth. The bottom portion represents the vibrations of the vocal cords during the utterance.
Spectrograms like this help to show how speech is one continuous flow of sound. In fact, during speech we do not separate the words into individual parts. Our brains are intelligent enough to process the sound waves in real time and comprehend the words being spoken (as if the words were indeed separated out). I mention this as an illustration of how difficult it can be to process speech data. If the recordings include static noise or if the person speaking is using an accent that the speech recognition system does not know about, then the quality of the processing will go down. But despite limitations like this, there is still very much information that we can glean from speech data.
Sentiment and Emotion Analysis
Speech and text processing both analyze the structure of the data. But, as human beings we do not produce language for the sake of analysis. We produce language as a communication tool to describe our experiences with life. That experience is most often emotional in nature. So, in order to more fully comprehend why a person behaves the way they do we need to include their emotional experience in our analysis.
Sentiment is the process of applying a quantification to the emotional experience so that the numbers applied can be computed and aggregated to larger bodies of text, summarized over categories, and used to predict future outcomes. For example, if I say, “I was very pleased with the service at this location,” I know that the experience was a positive one. The part of the sentence that triggered the positive sentiment is the verb “pleased”. Most sentiment analysis systems apply a number to this word such as +1 or +2. More sophisticated systems will take into account that “very” increments the value in some way.
The strength in this NLP approach is the ability to recognize an emotional experience. The weakness is that numbers take the place of actual emotions, thus possibly losing the richness of human experience in the quantification. If we use words to communicate our feelings and experiences, then one could argue that relying on the semantics of the words themselves leads to more rich analysis of emotional statements. There is a potential spectrum of dozens of emotions. One possible approach is to tag each emotion word with a position in the emotion spectrum and then feed that information into a predictive model as a feature. Regardless of the approach, however, the words used become the nucleus of emotion for the model.
Conclusion
When it comes to human experience, one cannot disregard comments produced by the people who constitute the target audience. These people are constantly talking about their experiences and billions of them share their ideas on the internet. By using NLP technology to understand what they say when given an open opportunity to do so leads to a much richer understanding of habits and choices that lead to actions.
Contact Mosaic today to see how we can help you design and deploy NLP



1 Comment
Sundar Varadarajan · June 8, 2016 at 3:38 pm
Can’t agree more.
Wrt Text Processing (use of NLP), information extraction using linguistic parsing, can be enhanced with the use of layers of knowledge specific to the problem area or domain. For example, if the domain is in the context of financial news – looking for extracting specific information wrt. events of specific interest such as mergers/acquisitions, or new product announcements, etc., domain-specific knowledge layer(s) can include the typical dictionaries/thesauri of words and phrases in the domain, patterns of expression of such events in the domain, etc. to make the information extraction more accurate, relevant and thorough. (More details on this also in: http://link.springer.com/chapter/10.1007/978-1-4471-0649-4_17).
Also, wrt speech processing, and sentiment&emotion analysis, this provides an interesting thought of using speech processing (analyzing the sound waves) to increase the accuracy in quantification of sentiment+emotion analysis.